The Diagrams are stored in clear text files in XML format. As opposed to the proprietary storage format of of other modelling tools.
By storing the data in clear text, the diagrams or other project entities can be stored in a central version control software, like github. We live in a world where all development artifacts are stored in repositories like github for easy access by all team members.
The other value of a tool like github is to be able to compare versions between commits. Thus, storing the diagram in clear text facilitates this kind of comparison tool.
A Project is a conceptual container for all of the various diagrams and other artifacts associated with a single development project.
A normal process would start with a Business Process Model (Swim Lane) and then a Data Flow Diagram. These would be followed by a Data Model of the system. The first two analysis diagrams should be able to link to entities in the Data Model.
The data model should live inside a project so that all versions of a model are available and can be displayed over time.
Data Models change over the time-span of a project as new requirements are discovered and as the development team makes stylistic decisions about what data to store, size, data type, etc.
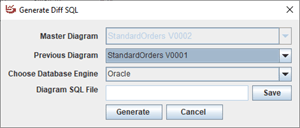
With multiple versions available, they can be compared by the tool and change DDL created. This is one of the most boring administrative tasks of the owner of the data model and needs to be automated.
Data Excelerator has the ability to compare two versions of a diagram and generate change DDL. This DDL code can then be given to the DBA group to implement in the target databases. Generated change scripts should result in fewer errors, less testing, and less work for the Modeler.
Each data model is a design time artifact. It is a model of what the business problem being solved looks like. It should be independent of the implementation database. This is why all modeling is done using a high level dictionary data type library. If the user wants to use data type specific to the back-end, they can add them to their own list.
From the single source of truth data model, the DDL can be generated for the appropriate database engine. Sometimes, the database is mirrored using different engines, so the value of choosing the database engine as the last step is quite useful.
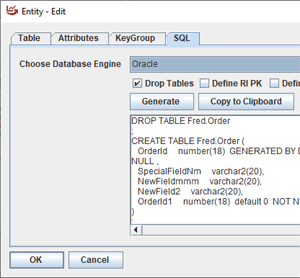
Using generic data types at design time frees the designer from worrying about which database engine they will be using when it should not be a consideration.
The reality is that each competing database engine will have an equivalent data type to one that the others have. It is simply a question of mapping the concepts to each other and then using them appropriately.
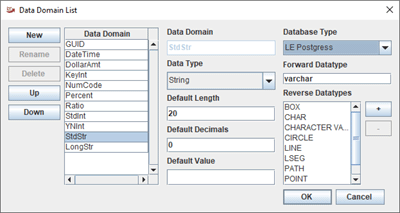
For forward engineering, it is a simple process of choosing the desired backend data type desired for a particular Data Domain. When more precision is needed, the user can add more Data Domains to the default set.
For reverse engineering, the user must make decisions about which backend data type(s) map to which Data Domains. There may be several data types that will merge into a single logical Data Domain. The mapping is inherently many to one and can only have one occurrence for each engine data type. So the creation of specialized Data Domains can be used to precisely control reverse engineering.
Since Data Excelerator is intended to follow the adage of "the design being the master", it is assumed that any reversing of the database will be done infrequently and will only form the starting point of a design process. Once the designer has saved themselves the typing effort of loading the tables and fields into the model, they can then modify the data types as appropriate for forward engineering only.
While a modeller is designing the Data Model, they would be advised to document the definitions of the various fields they are creating.
They should also add the list of valid values for a field, which is also useful for the programmers.
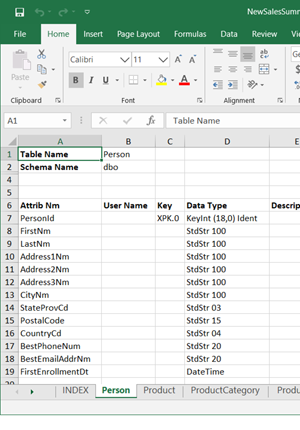
Printing this data in a format that is easily shared among the end-user community will help facilitate the acceptance of the design process.
The output format is to excel with an index tab followed by one tab per entity defined in the model. The set of fields printed by the process is configurable.
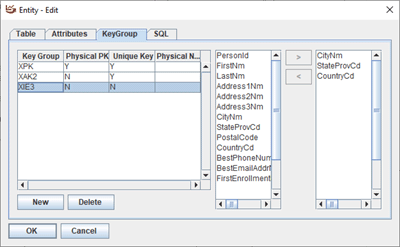
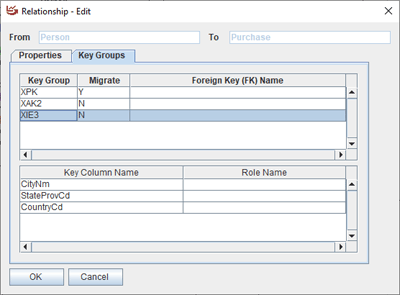
Each table can have multiple keys, unique or otherwise, any of which can migrate to a child table. Only one primary key is per table.
Only one relationship is allowed between any two tables. To understand the details of the relationship, edit the relationship. At that time, the designer can decide which, if any, of the keys should live on the child table. A unique key from the parent denotes a standard parent-child relationship. However, a non-unique key allows the two tables to be grouped and aggregated together.
If there is an index on the migrating key on the child table is an implementation decision made by the DBA.
People think in their own language. It would be better if a tool was able to handle other languages than English. For instance, in Canada, all systems must support both official languages. (English and French)
Data Excelerator supports any number of languages with ease. ALL strings in the program come from a properties file with a specific naming convention.
To add a new language, simply add a new file with the appropriate two character locale identifier. If you complete the translation, please send the file to us so that it can be made part of the deployed package.
If the current translation is not correct, please feel free to make changes. Please send the latest file to us to absorb your changes.
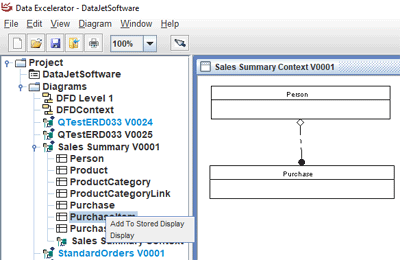
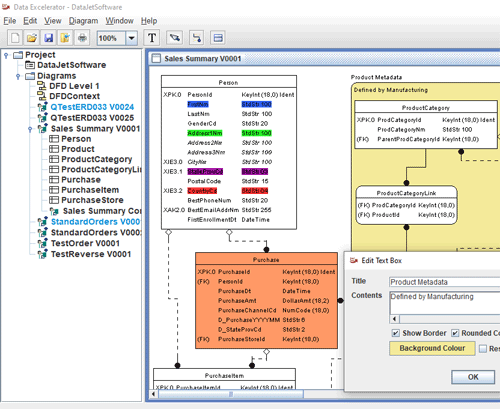
A Data Model diagram can have a stored display diagram attached to it as a child diagram. The child diagram is an independent copy of the parent diagram and can have a subset of the tables and relations on it as well as different display options.
For example, a context diagram can be created with all of the tables displayed but in a more compact form than with all attributed being displayed.
A subset of tables can be collected which are the set being worked on by a project. Or a subset that correspond to a specific schema. These groupings of tables can be generated independently
The master Diagram holds the most up to date version of the tables, attributes and relationships. When the master Diagram is updated, the stored displays can be refreshed as desired. If a parameter is turned on, then it will be refreshed on open.
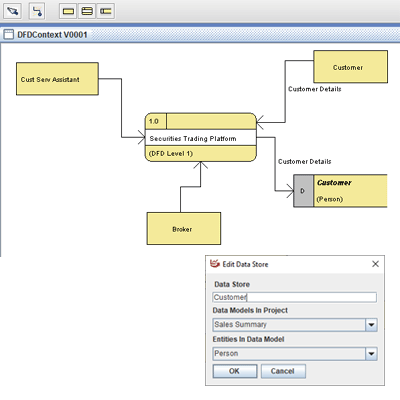
A Data Flow Diagram (DFD) provides a visual representation of the flow of data within a business. By drawing a Data Flow Diagram, you document the information supplied to someone who take part in system processes, the information needed in order to complete the processes and the information needed to be stored and accessed.
Data Excelerator has the usual functionality of the three different objects in the DFD diagram type as displayed along the top tool bar. Once a process is defined, it can be linked to child processes to have the level of detail that the business requires to document its system behavior.
Because it can host Data Model diagrams, the Data Store object in the ERD can be linked to a Data Model Diagram and a table within that diagram. For a DFD, this shows an extra level of detail.
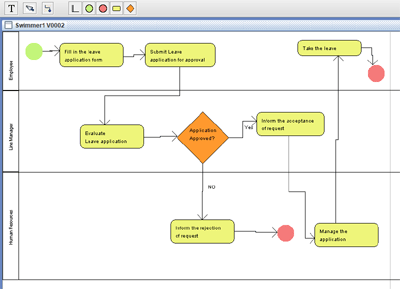
Business Process Model and Notation (BPMN) is a well-known modeling standard to use in business process modeling. It is often used at the beginning of an analysis of a business to document who talks to who, when, and about what. Knowing the answers to these questions about the existing business process allows an analyst to document the flow of data (DFD) in the business and to document the data structure (ERD).
Data Excelerator has the usual functionality of the different objects in the Swim Lane diagram type as displayed along the top tool bar.